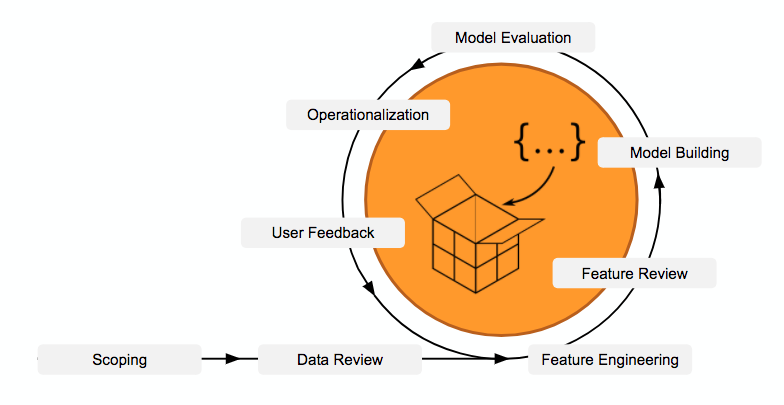
Over the machine learning projects that I have participated this was the workflow I have practiced that best defines and which go through all the most important steps.
1. Scoping
First you scope the problem that you want to solve. Is that a classification or clustering problem? Do you have enough data? If not can we collect it. Where will our machine model be used? What is the latency requirement? How can we re-train our model? What is a good model evaluation?
2. Data Review
Jupyter Notebook and “import pandas as pd” are my best friends. Do a lot of summaries (min, max, mean, median etc.). Check for outliers. Understand the definition of each column. For classification, check target variables. A lot of plots… matplotlib and seaborn.
3. Feature Engineering
Normalize data, convert data so that it can be used by scikit-learn e.g. one-hot encoding for categorical variables or text data into vectors (bag of words, tf-idf), clean data etc…
4. Feature Review
Review transformed input data before the modelling. A lot of errors can happen during a transformations e.g. in one hot encoding we forgot one column…
5. Model Building
Start with the simplest model e.g. for classification take linear models then use tree-models and then go to neural networks.
6. Model Evaluation
Evaluate your model. Use simple split then cross-validation. MSE, RMSE for regression. Accuracy, precision, recall and F1 for classification.
7. Model Accountability
Confidence in the features our model is using, and thus would feel more comfortable deploying it in a system that would interact with customers. Feature importance, marginal effect and LIME are great tools.
LIME is a black-box explainer allows users to explain the decisions of any classifier on one particular example by perturbing the input and seeing how the prediction changes.
8. Operationalization
Bring your model into production. Only models that are out generate business value. Pickle your scikit-learn model or export your Tensorflow model. Create RESTful API for web applications. Embed it on your device if latency is important.
9. Get user feedback and re-iterate to improve
Offline evaluation uses historical data. Focusing more on ML related metrics. It is cheap yet biased. Online evaluation involves A/B test, measuring business-related KPIs. It is expensive but telling you the true value of the model.